
This paper was written as part of the lecture “Ultra Large Scale Systems” at Stuttgart Media University. In the lecture, we decided to take a closer look at video platforms such as YouTube and examined several sections of its large-scale architecture. In order to approach this, a possible architecture of such a platform was outlined. This paper focuses on the sub-area of event processing and video uploading.
Overview
Architecture
To implement a large scale video processing pipeline that requires a variety of different services we decided to work with an event based architecture.
At the core, Apache Kafka lays the foundation to handle communication between services. Apache Kafka is an event streaming platform. It can be used to build a ”central nervous system“ for an organization. It was originally developed by LinkedIn in 2010, but became part of the Apache Foundation in 2012 and has spawned its own company, Confluent. It is written mostly in Java and is Open Source. Kafka focuses on storing and processing data streams and provides many interfaces to other systems for loading and exporting to third-party systems.
The following figure shows a full conceptional video processing pipeline:
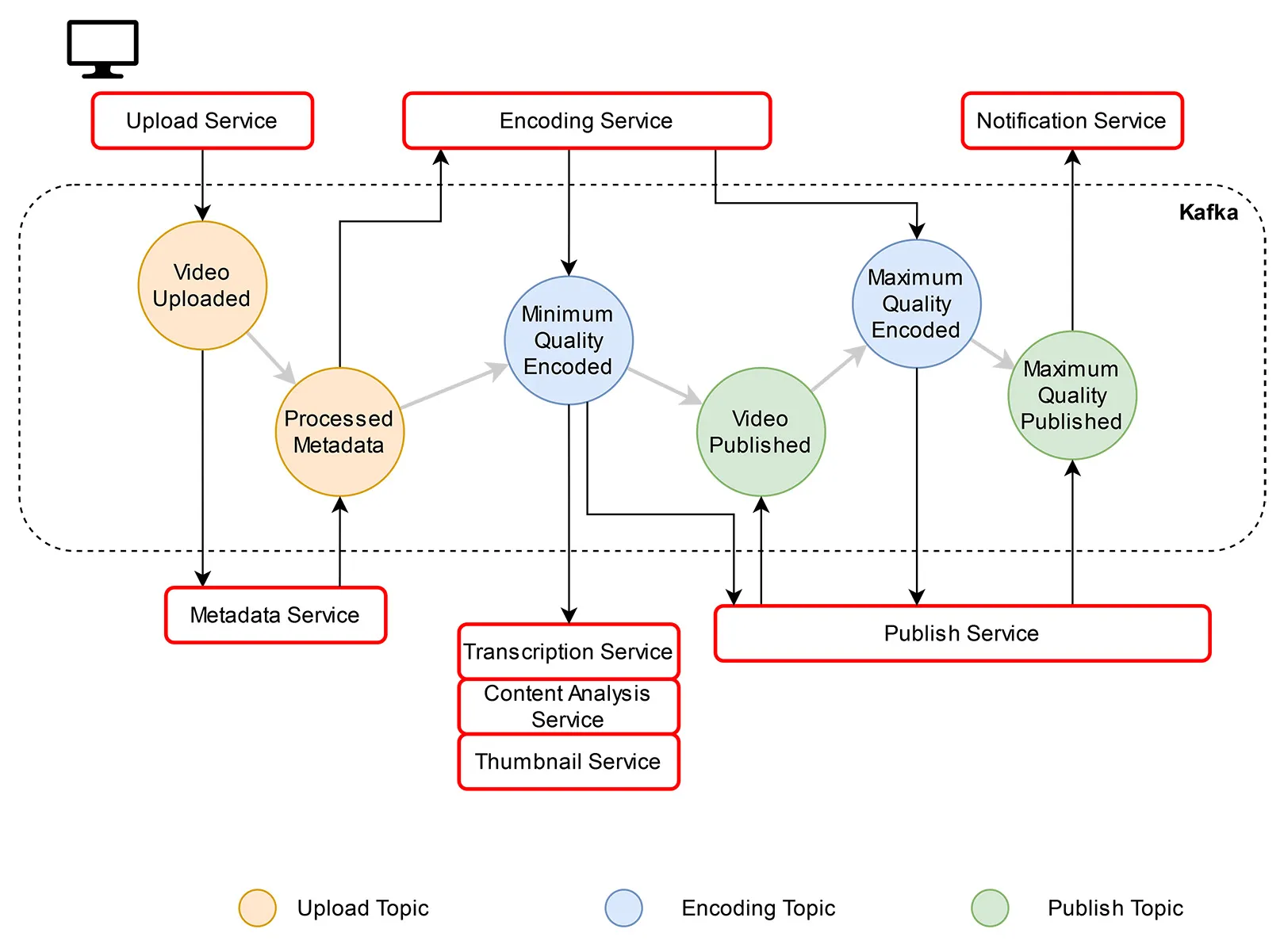
Encoding
To reduce storage load, costs, and ensure worldwide support across all devices, uploaded videos are to be encoded in parallel through a chunking mechanism. The preferred codecs are AV1 and VP9, as they are license-free and offer comparable or better performance than paid alternatives.
Implementation
Based on our cost calculations, encoding will be performed on CPU cloud instances as they generate lower costs compared to GPU-based encoding, because the generated files require less storage space / better compression. However, for automatic transcription of video content and the associated provision of automatic subtitles for accessibility, GPU instances are used due to significantly faster processing times compared to CPUs.
Paper
If you want to read more about our proposed architecture consider reading our paper: Download