The lecture programming intelligent applications consists of weekly experiments to train all kinds of current artificial intelligence models. It challenges students to not only complete the provided exercises, but to also perform additional experiments in the context of the current exercise. In the context of embeddings and transformer models I chose to attempt to train a transformer model to translate from german to “schwäbisch”.
In the previous experiment we already used the BERT model for sequence classification, that is why we initially played with the thought to use it for this experiment as well. In the following abstract we are going to explain why we ended up using T5.
Having an encoder-only architecture, BERT is performing well on tasks like Text Classification, Token Classification, Fill-Mask and Question Answering, but is not well suited for machine translation. (Source)
Therefore we had to look out for another model with a better suited architecture and came across T5 which is also used in Huggingfaces translation documentation. T5 uses an encoder-decoder architecture and “models every problem in the form of text-to-text format. The input and output will always be in text format.” (Source)
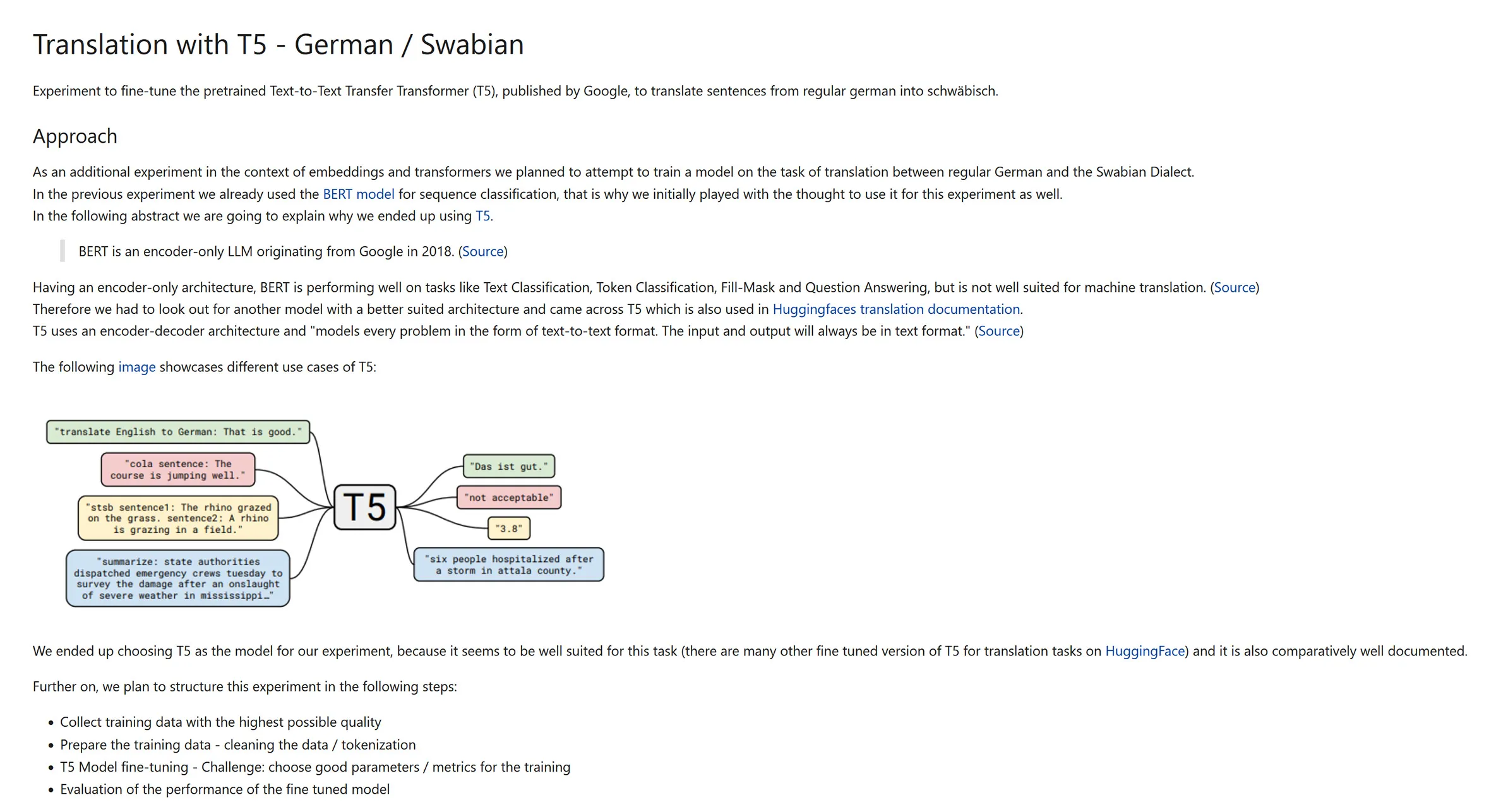
The following image showcases different use cases of T5:
We ended up choosing T5 as the model for our experiment, because it seems to be well suited for this task (there are many other fine tuned version of T5 for translation tasks on HuggingFace) and it is also comparatively well documented.
Table of Contents
Open Table of Contents
Collect training data with the highest possible quality
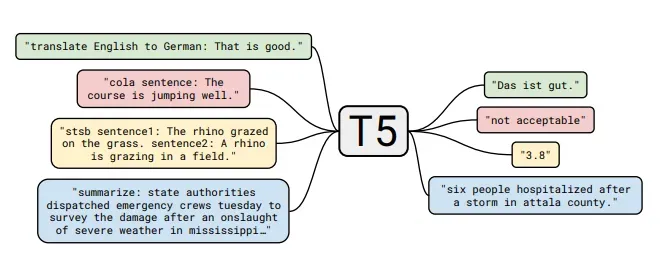
Ideal for the fine tuning of transformers in general would be a large corpus of texts that are available both in the source language, german, as well as in the target language swabian. Unfortunately we did not find a lot of swabian content in the web. The only data source we came across was Schwaebisch-Schwaetza.de
This page contains a dictionary with about 12000 entries, of which around 3000 are simply word to word translations. These are obviously not ideal for the training of a transformer as they to not contain information about their use cases and relationships to other words. At the given time this was still the best data source we could find, therefore we implemented a WebScraper to get the data from the dictionary and transfer it into a csv file. The csv file contains the Data from: https://www.schwaebisch-schwaetza.de/schwaebisches_woerterbuch.php:
Another attempt to get swabian training text was to get movie subtitles for well known swabian tv shows like “Die Kirche bleibt im Dorf”, but unfortunately, even though the characters are talking in swabian, the subtitles are still in regular german.
Prepare the training data - cleaning the data / tokenization
Clean the data
In the following example we can see that there are references to the French language for some words. We therefore implemented the function remove_frz to remove these from our data.
{'translation': {'de': 'Lebewohl, Auf Wiedersehen, Tschüss', 'swb': 'Adee (frz: adieu)'}}
After processing the dictionary entry looks like this:
{'translation': {'de': 'Lebewohl, Auf Wiedersehen, Tschüss', 'swb': 'Adee'}}
As you can see in the example above, for some words there are multiple translations available. Our first implementation was the remove_multiple method, which simply removed the other entries except for the first one. Later on we figured that using this method would mean that we’d lose valuable data. That is why we implemented the split_multiple function. Instead of removing the other translations the function split_multiple splits the translations and therefore keeps the multiple meanings of a word. After processing the first translation looks like this:
{'translation': {'de': 'Lebewohl', 'swb': 'Adee'}}
Another problem were curses that are not translated in the dictionary. Instead the german translation is So schimpft halt nur ein Schwabe!:
{'translation': {'de': 'So schimpft halt nur ein Schwabe!', 'swb': 'Dei Geseir machd me ganz schallu, Du bisch doch riegalesdomm, wo De d’ Haud anregd!'}}
We removed those entries from the dataset entirely.
Preprocess the data
First of all we shuffle our data and split it into training and test data. In the next step, the preprocess_function, we tokenize our data. As T5 formulates all problems in a text to text format we add the prefix “translate German to Swabian: ” ahead of the inputs / the german entries.
Additionally we tokenize the swabian translations that will serve as our labels.
T5 Model fine-tuning - Challenge: choose good parameters / metrics for the training
Custom metrics
After the preprocessing and preparation of our data we can now attempt to train our model. Therefore we setup custom metrics to get a better understanding of how our model develops and performs over the training steps.
As one metric we use the BLEU score:
BLEU (Bilingual Evaluation Understudy) is a score used to evaluate the translations performed by a machine translator.
It works in the following way:
It is calculated by comparing the n-grams of machine-translated sentences to the n-gram of human-translated sentences.
Source: https://www.geeksforgeeks.org/nlp-bleu-score-for-evaluating-neural-machine-translation-python/
As our other additional metric we get the average generated sequence length.
Training
First of all we get the pre-trained T5 model and make sure that it runs on the GPU. To get more information on our training setup and parameters you can download the Jupyter Notebook file at the end of this post.
Evaluation of the performance of the fine tuned model
The following chart shows a plot of the metrics we collected throughout training:
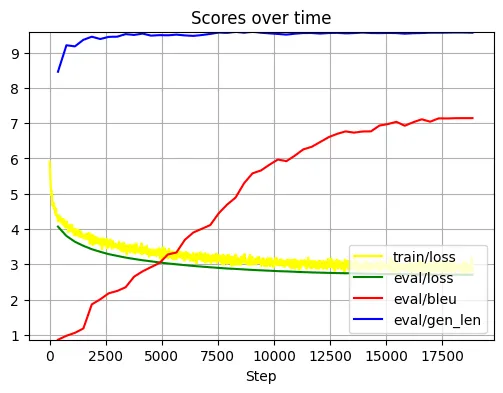
As you can see the loss is decreasing, as expected, and the bleu score as well as the generated length are increasing. The training seemed to have worked. But how does the model perform in practice?
First of all we test how the model performs on sentences from the dataset. We can simply use our trained model like this:
from transformers import pipeline
translator = pipeline("translation_de_to_swb", model="german_swabian_model_04_29_complete")
translator("translate German to Swabian: Ein halber Rausch ist nur rausgeworfenes Geld.", max_length=400)
Which leads to the result:
[{'translation_text': 'An halber Rausch isch bloß rausgworfas Geld.'}]
In the next step we test the model on other sentences. Here are a couple of more examples:
translate_into_swb("In ein paar Minuten kann man mehr versprechen, als in einem Jahr einhalten.", translator)
'In a paar Minuten ko mr mehr versprechen, als en a Jahr ahaltend'
translate_into_swb("Du musst Deine Nase auch überall reinstecken!", translator)
'Du muasch Dei Räddz au überall reschdagga!'
translate_into_swb("Frauen haben immer Recht, besonders die Eigene!", translator)
'Frauen hann emmr Recht, insbesondere d’ Eigen!'
translate_into_swb("Über Baden lacht die Sonne, über Schwaben die ganze Welt.", translator)
'Über Bada lacht d’ Sonne, über Schwaba d’ ganze Welt.'
We can conclude that the translation works surprisingly well considering that the training data is not really suited for a transformer model.
More information on how we implemented the training: Download Notebook