
In my blog post How we improved our transcription performance by over 60% I explained how we managed to improve Ton-Texters transcription performance. In this post we are going to discover how we managed to improve its performance even further through the introduction of the whisper-large-v3-turbo model.
Table of Contents
Open Table of Contents
Whisper Large v3 turbo
We’re releasing a new Whisper model named
large-v3-turbo, orturbofor short. It is an optimized version of Whisperlarge-v3and has only 4 decoder layers—just like thetinymodel—down from the 32 in thelargeseries. Across languages, theturbomodel performs similarly tolarge-v2.
With this release we can get the performance of the previously state of the art large-v2, but with much higher transcription speeds. The most popular metric to measure transcription quality is the word error rate. It compares the transcription with the original transcript and calculates an error rate based on how many words were correct, missed, replaced or incorrectly inserted.
The following chart shows the word error rates of the whisper models large-v2, large-v3 and large-v3-turbo.

As we can see, in most cases the turbo model, even though its just 1/8 of the size of the large-v2 performs comparably. In our most important languages German and English the WER is 6.9% and 10.6% respectively.
Speed
On a AWS g4dn.xlarge Instance, that is equipped with a Nvidia T4 GPU, the transcription of a 1:37h podcast took less than 4 minutes. The entire process took around 9 minutes, including the speaker diarization, the segementation of the audio file and the export of the transcript in srt, txt and docx files.
This is equivalent to a real-time factor (The amount of time the transcription takes in comparison to the audio length of the provided audio file) of around 11.
Through the introduction of the large-v3-turbo model we managed to increase the real-time factor of our transcription pipeline from around 8x to around 11x !
In our logs we can see the individual steps of the process and the time it takes for each step:
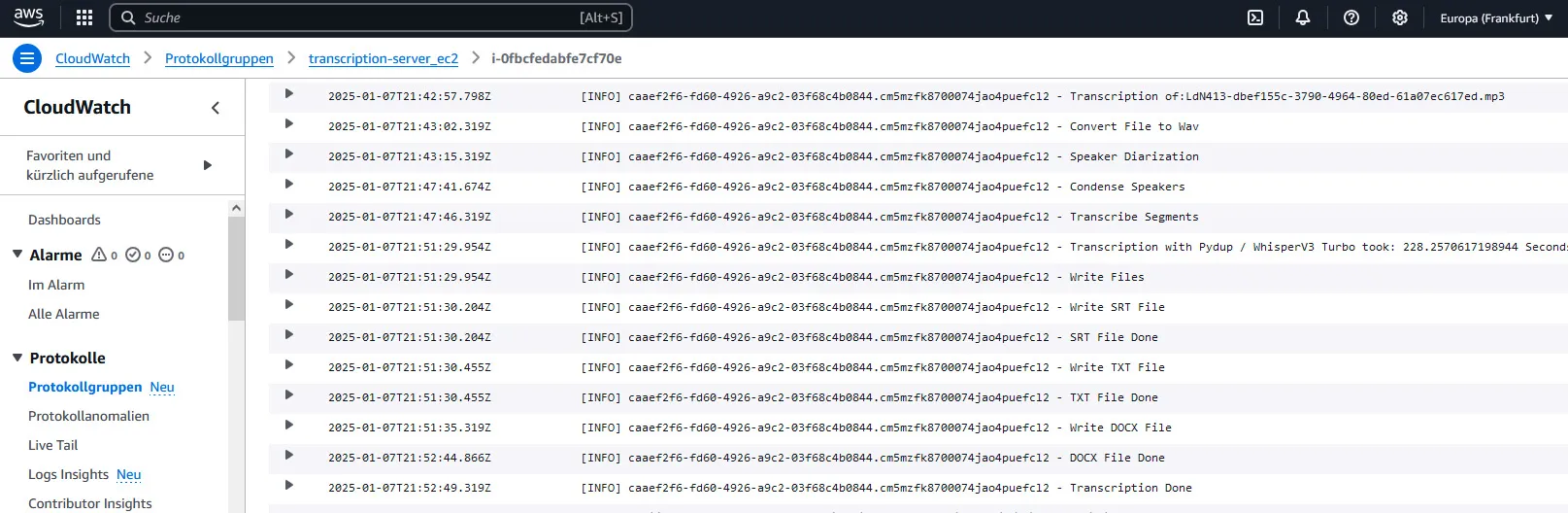
Read more about how we use centralized logging in AWS Cloudwatch here:
Many components - one central place for logs - how we use AWS Cloudwatch
Usage
As described on the huggingface model page, we load the model on the gpu:
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_id = "openai/whisper-large-v3-turbo"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
pipe = pipeline(
"automatic-speech-recognition",
model=model,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
chunk_length_s=30,
batch_size=16,
torch_dtype=torch_dtype,
device=device,
)
Work with segmented audio
Just like in the previous state of Ton-Texters transcription, we use Pydub to get sections from the original audio file based on the speaker diarization performed with Pyannote:
# load audio
audio = AudioSegment.from_file(filename, format="wav")
# convert to expected format
if audio.frame_rate != 16000: # 16 kHz
audio = audio.set_frame_rate(16000)
if audio.sample_width != 2: # int16
audio = audio.set_sample_width(2)
if audio.channels != 1: # mono
audio = audio.set_channels(1)
total = speaker_segments[-1].out_point
for segment in speaker_segments:
with tqdm.tqdm(total=total) as progress:
# Slice Audio with pydup
segment_in = int(segment.in_point*1000)
segment_out = int(segment.out_point*1000)
segmentAudio = audio[segment_in:segment_out]
...
These Pydub segments can be passed to the whisper model like this:
result = pipe(np.frombuffer(segmentAudio.raw_data, np.int16).flatten().astype(np.float32) / 32768.0, return_timestamps=True)
Be aware of the different structure of the result object in comparison to the original whispers result object. Instead of segments we do receive an array of chunks. Instead of start and end timecodes, the timecodes are summarized in a timestamp tuple. Each chunk looks like this:
{'timestamp': (183.8, 184.3), 'text': 'So Sora came out, and this thing looks amazing.'}
Conclusion
With the usage of the whisper-large-v3-turbo model we improved transcription quality substantially in comparison to the previously used small model of the initial release of Whisper. In addition to that the transcription speed increased by around 40%. Ton-Texters real-time factor is now at about 11x.
To test the capabilities of Ton-Texter we used JMeter, a tool to simulate large traffic / to stress test an application, to see how long it would take Ton-Texter to process a sudden demand of 10 hours of audio material, divided in a number of 40 files with different lengths.
With our updated pipeline it took Ton-Texter a little under an hour to transcribe all files, as you can see from our Cloudwatch Logs:
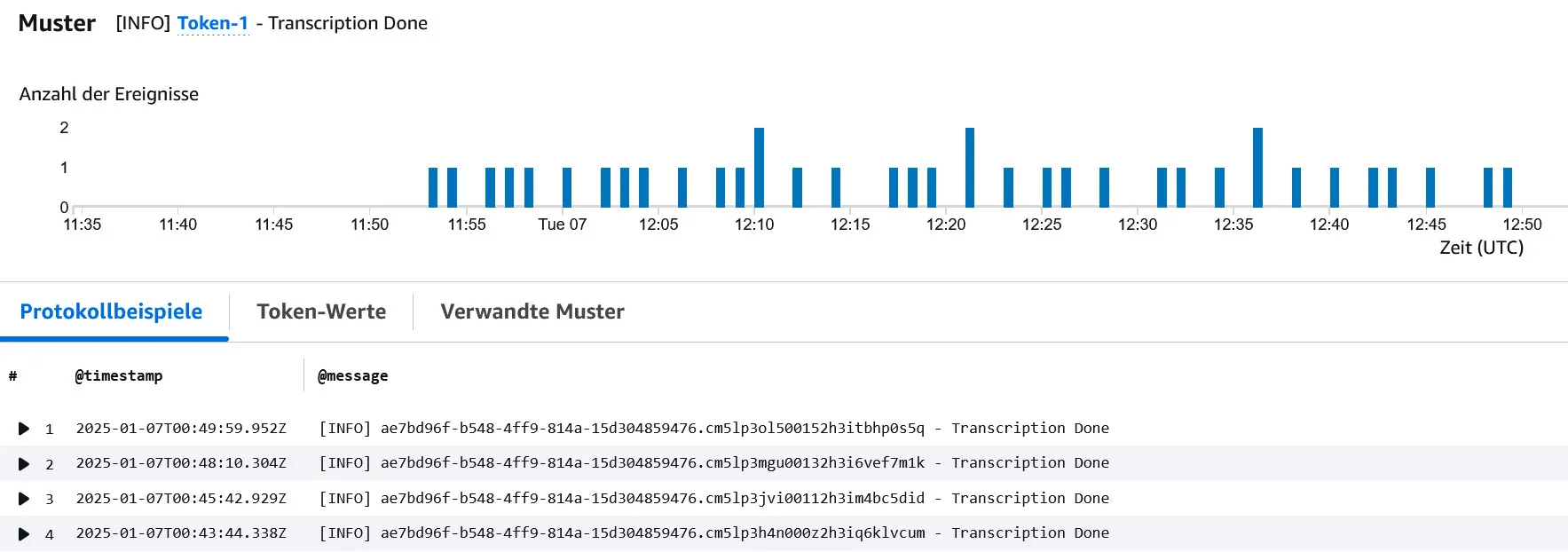
With our previous implementation it would have taken at least 15-20 minutes longer - success!
If you want to read more about how we stress test our application consider reading:
Can Ton-Texter keep up?! - simulating high traffic with Apache JMeter